
07 Jun QLIK EN BIG DATA: CONOCE SUS SOLUCIONES, POTENCIALIDADES Y ALCANCES.
Big Data está tomando cada vez más una gran fuerza en distintas empresas en todo el mundo para el tratamiento de sus datos, ya sea por su alcance de trabajo con grandes cantidades de datos, rapidez en su información y encontrar respuestas donde antes no se veían. En este artículo conocerás los alcances que tiene Qlik al trabajar con Big Data.
La capacidad de las soluciones en Qlik genera un gran valor para el negocio, no solamente en el científico de datos, si no también genera un mayor retorno de las inversiones que realizan las empresas en el Big Data ( Conoce más sobre Big Data aquí).
Qlik ofrece una combinación única de soluciones en las cuales pueden ser aplicadas dentro del mundo del Big Data, éstas son:
- Una vista completa de su información: Las simples herramientas de integración que posee Qlik, permiten mezclar múltiples fuentes de información dispares para proporcionar una imagen completa del negocio de las organizaciones. Estas soluciones en Qlik permite conectar fácilmente a cualquier fuente de datos, como por ejemplo, fuentes contenidas en Web, Excel, Sap, Salesforces, y fuentes de big data como Hadoop, Teradata y Cloudera.
- Análisis, exploraciones Interactivas y en forma libre: El motor asociativo de Qlik (QIX), nos permite asegurar que cada componente de los datos se asocia dinámicamente con cualquier otro dato, en todas las fuentes de datos. Estas asociaciones pueden ser útiles si hay cientos o miles de productos, clientes, zonas geográficas, etc. Estos universos de datos extremadamente grandes, se pueden dividir en segmentos realizando pocos clics, en lugar de navegar por miles de elementos. Con Qlik, el contexto y la relevancia van de la mano, y rápidamente llevan a lo que parecía ser un problema de Big Data a algo que es bastante manejable y sin ninguna programación o habilidades avanzadas de visualización.
- Múltiples métodos para soportar Big Data: Debido a que en las organizaciones, los casos de uso y las infraestructuras son muy dinámicas, Qlik Ofrece múltiples técnicas, que se pueden usar en forma individual, o en combinaciones, para satisfacer las necesidades de Big Data.
– En Memoria.
– Segmentación y Chaining.
– On Demand App Generator.
– Associative Big Data Indexing.
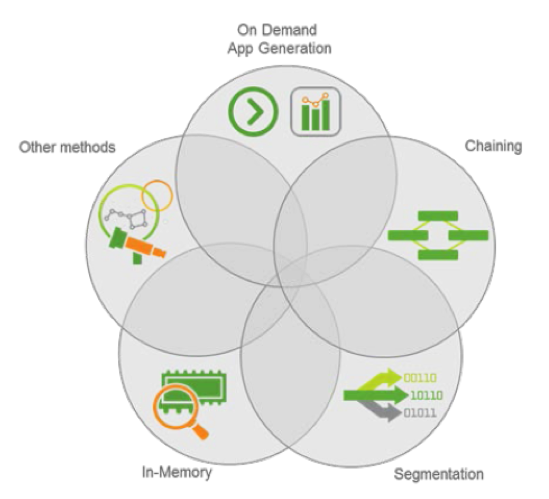
Metodologías de Big Data en Qlik
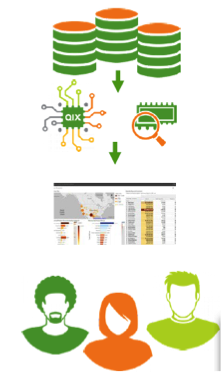
ENFOQUE QLIK EN MEMORIA
- Utilizando el motor asociativo de Qlik (QIX), permite una compresión de datos de hasta el 10% del tamaño original.
- Carga un índice de datos altamente comprimido en Memoria.
- Soporta alta interactividad con la experiencia del usuario.
- Permite una búsqueda asociativa y análisis de todo el conjunto de los datos.
- Permite de 100 millones a miles de millones de Registros.
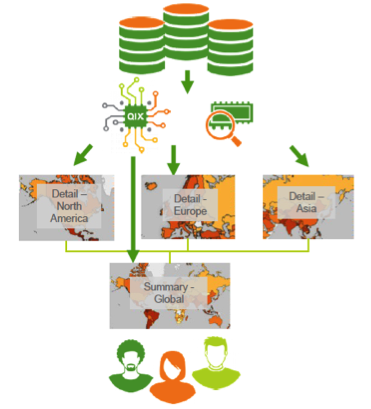
SEGMENTACIÓN Y CHAINING
- Se crean vistas de datos segmentados, en vistas específicas por enfoque y luego encadenandose en vistas separadas entre sí.
- Divide la información en múltiples aplicaciones realizando Drill Down.
- Utiliza datos altamente comprimidos como un índice en memoria.
- Admite 100 millones de registros a miles de millones de filas por aplicación segmentada.
ON DEMAND APP GENERATOR
- Consiste en Capacitar a los usuarios para que creen aplicaciones de análisis diseñadas cada vez que seleccione una porción de una fuente de datos muy grande.
- Selección de una dimensión para generar una App con datos analíticos.
- Realización de Slices de datos en Apps bajo a demanda.
- Convertir el Big Data en pequeños análisis de datos.
- Impulsado por usuarios comerciales gobernados por TI.
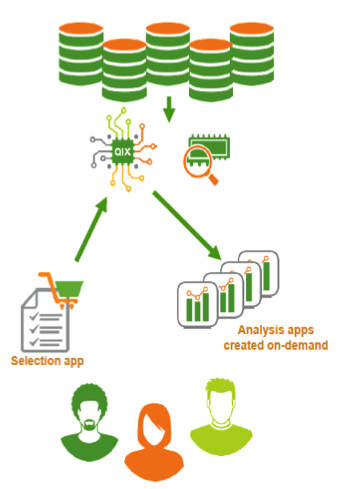
ENFOQUE DEL ON DEMAND APP GENERATOR
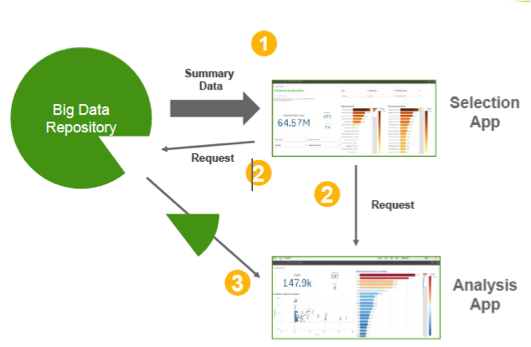
1) El usuario visualiza los datos en una App resumida y selecciona una porción de los datos para la app de análisis
2) El usuario solicita que la aplicación de análisis se genere.
3) Se extraen los datos de origen y se crea una App de análisis.
4) Repetir los pasos 1 y 3 tantas veces sea necesario.
TRABAJOS FUTUROS EN BIG DATA (Associative Big Data Indexing):
Las capacidades de conectividad, preparación e integración de datos son fundamentales para el objetivo de permitir a los usuarios acceder a los datos donde quiera que se encuentren, sin estar limitados por su tamaño o complejidad. Se está planificando una inversión significativa en capacidades de datos para 2018 y más allá, incluyendo mejores características inteligentes de autogestión y preparación de datos en Qlik, y dentro de las capacidades del big data se presentará Associative Big Data Indexing.
Associative Big Data Indexing se centra en gran medida en una nueva capacidad asociativa de indexación de datos, que proporcionará una experiencia asociativa completa además de las fuentes de Big Data, dejándola en donde residen los datos. Esto permitirá que el motor de Qlik almacene información sobre datos residentes en fuentes como Data Lakes y Hadoop, sin la necesidad de cargar todos los datos en la memoria. Esta capacidad se distribuirá, aprovechando el poder del motor asociativo de Qlik para ofrecer un descubrimiento rápido e interactivo a través de enormes conjuntos de datos.
Autor: Julio Lobos – Consultant Leader A10